递归语言模型登场!MIT华人新作爆火,扩展模型上下文便宜又简单
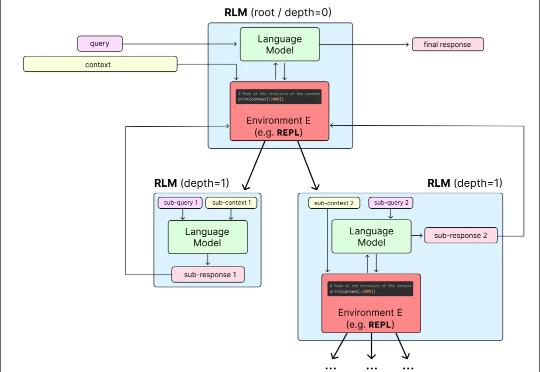
递归语言模型登场!MIT华人新作爆火,扩展模型上下文便宜又简单目前,所有主流 LLM 都有一个固定的上下文窗口(如 200k, 1M tokens)。一旦输入超过这个限制,模型就无法处理。 即使在窗口内,当上下文变得非常长时,模型的性能也会急剧下降,这种现象被称为「上下文腐烂」(Context Rot):模型会「忘记」开头的信息,或者整体推理能力下降。
来自主题: AI资讯
8153 点击 2025-10-17 16:12